library(tinytex)
library(knitr)
library(dplyr)
mtcars.data <-
as.data.frame(mtcars) %>%
mutate(transmission = factor(case_when(am==0~"automatic",
am==1~"manual")),
engine=factor(case_when(vs==0~"V-Shaped",
vs==1~"Straight")),
cylindars=factor(cyl))Bayesian Analyses - Effective Reporting
So how do we report the results of a bayesian analysis. As mentioned previously, at a minimum you need to report either the Bayes Factor or the Posterior Probabilities. However that is not typically sufficient or reproducible.
Fortunately there are reporting guidelines set out in (Kruschke 2021), which includes the rationale and importance for each of these. These are known as the Bayesian Analysis Reporting Guidelines or BARG. Lets go over them, and some ideas of how we could do this with our example analysis of mtcars evaluating the relationship between transmission type and vehicle weight
Preamble
Justify why you are using a Bayesian approach
This is important as it is likely most readers will be unfamiliar with this approach and will be hoping to see conventional p-values.
For each of these I will show some sample language
We used a Bayesian approach here because it provides a continuous probability interpretation of the hypotheses being tested
Explain the goals of the analysis
To determine whether transmission has a relationship with the weight in the mtcars dataset.
Model Specification
Describe dependent and independent variables
This should be done in the results section so it is clear what the comparison is.
We evaluated whether the vehicle had an automatic or manual transmission and how that related to the weight.
Likelihood function and model parameters
Lets look at our analysis from before. We used a bernoulli family fit (this is a binomial regression). This is the default analysis:
# Fit the model
library(brms)
# directory for cached model fits — brms reuses these on re-render
dir.create("fits", showWarnings = FALSE)
binomial.fit.default <- brm(transmission ~ wt,
data = mtcars.data,
family = bernoulli(),
file = "fits/barg-binomial-default",
file_refit = "on_change")As we will shortly see its helpful for us to be more thoughtful about the choice of priors which by default are flat with no upper or lower bounds. The intercept is set roughly to a Student’s t distribution centered around 3 tons.
prior_summary(binomial.fit.default) %>% kable(caption="Prior summary for effects of transmission on engine type")| prior | class | coef | group | resp | dpar | nlpar | lb | ub | tag | source |
|---|---|---|---|---|---|---|---|---|---|---|
| b | default | |||||||||
| b | wt | default | ||||||||
| student_t(3, 0, 2.5) | Intercept | default |
We have some information already, for example we know that globally about 56% of vehicles are automatic, so 44% are manual. With transmission coded as a factor with levels c("automatic", "manual"), brms models P(manual) — the second factor level is the “success” outcome under bernoulli(). So the relevant intercept on the log-odds scale is the log-odds of manual:
\[\text{log-odds of manual} = \ln\!\left(\frac{0.44}{0.56}\right) \approx -0.241\]
We set this as the prior mean for the intercept, with a wide standard deviation of 5 (which on the log-odds scale spans roughly OR ≈ 1/22,000 to 22,000 — very weakly informative).
I don’t have a good sense of what I expect for the effect of weight (class b, coef wt), so I set that to a normal distribution centered at zero with a standard deviation of 5 and no boundaries. I would consider these weakly informative priors — they encode the right order of magnitude for the intercept but allow the data to dominate.
new.priors <- c(prior(normal(-0.241, 5), class = Intercept),
prior(normal(0, 5), class = b, coef = wt))
binomial.fit <- brm(transmission ~ wt,
data = mtcars.data,
family = bernoulli(),
sample_prior = T,
prior = new.priors,
file = "fits/barg-binomial",
file_refit = "on_change")prior_summary(binomial.fit) %>% kable(caption="Prior summary for effects of weight on transmission type")| prior | class | coef | group | resp | dpar | nlpar | lb | ub | tag | source |
|---|---|---|---|---|---|---|---|---|---|---|
| b | default | |||||||||
| normal(0, 5) | b | wt | user | |||||||
| normal(-0.241, 5) | Intercept | user |
Using the bernouli family, the default is the logit link function.
The data were fit to a bernoulli distribution with a logit link function.
Prior Distributions
What was the prior probabilities set at. As noted above we set our priors to be this, including some justification:
The prior on the intercept was a normal distribution centered at the log-odds of a manual transmission corresponding to a 44% global manual-transmission share (\(\beta = -0.241\); based on worldwide automobile statistics), with a wide standard deviation of 5. For the prior on the effect of weight we used a normal distribution with mean zero and a standard deviation of 5 on the log-odds scale.
Formal Specification of the Likelihood Function
The Bernoulli family with a logit link is automatically implemented in brms, but explicitly: \(P(TYPE|\eta) = \big(1 / (1 + e^{-\eta})\big)^{TYPE} \cdot \big(1 - 1 / (1 + e^{-\eta})\big)^{1-TYPE}\), where TYPE is the encoded transmission (0 for automatic, 1 for manual; brms uses the alphabetical second factor level as the “success”).
This is implemented within brms so I think this is covered by our statement about the likelihood function.
Prior Predictive Check
This is to make sure that our priors are reasonable and fit the shape and values of our data. To do this we simulate some data from our priors, and compare that with the observed data. To do this within brms we will need to re-run our model but just sampling the priors:
binomial.fit.pp.check <- brm(transmission ~ wt,
data = mtcars.data,
family = bernoulli(),
sample_prior = "only",
prior = new.priors,
file = "fits/barg-binomial-prior-only",
file_refit = "on_change")Lets visualize these the solid line is the observed data with the lighter lines being those simulated from our priors. These look ok to me.
# Show density plot
pp_check(binomial.fit.pp.check, type = "dens_overlay", ndraws = 100)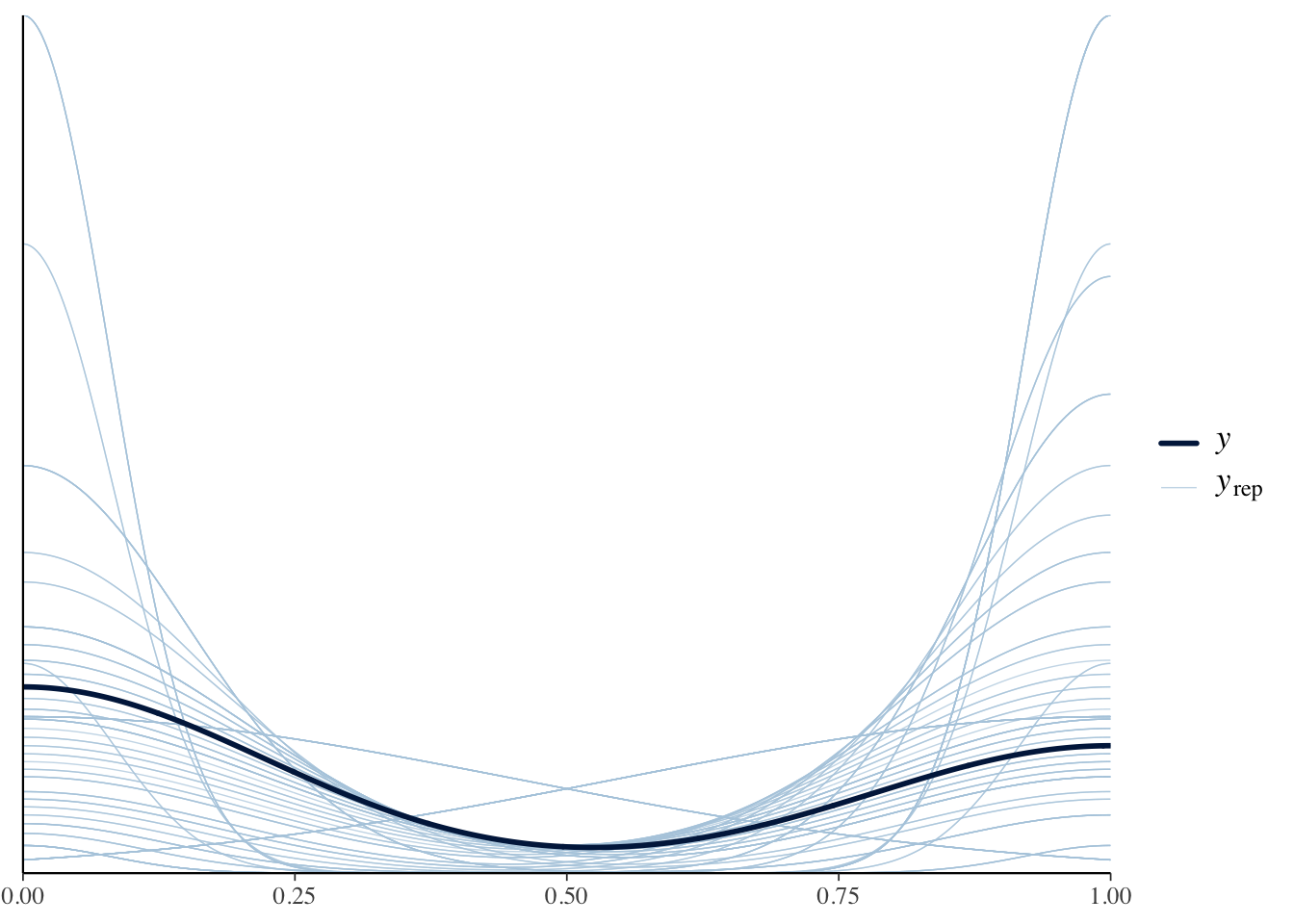
We did a prior predictive check and values from simulated from our prior distributions were similar to the observed data.
Reporting Details of the Computation
Software
It is good practice to cite the package and the version numbers for reproducibility.
We used the brms package version 2.23.0 (Bürkner 2021, 2017) implemented in R version 4.6.0 (R Core Team 2024).
MCMC Chain Convergence
This is given by \(\hat{R}\) or Rhat in brms, which is the same as as the PSRF (Position scale response factor) or the Gelman-Rubin convergence diagnostic (Gelman and Rubin 1992). We want this to be as close to 1 as possible (ideally between \(0.99-1.01\)). You could report this for each model, or just give a range of values.
We verified that the Gelman-Rubin statistic for chain convergence was between 1 and 1.01 for all model parameters
kable(data.frame(
Parameter = names(rhat(binomial.fit)),
Rhat = format(rhat(binomial.fit), nsmall = 5)),
caption="Rhat values for model testing the association between weight and transmission (should b between 0.99 and 1.01 for convergence).",
row.names = F)| Parameter | Rhat |
|---|---|
| b_Intercept | 1.0015581 |
| b_wt | 1.0026366 |
| Intercept | 1.0022817 |
| prior_Intercept | 1.0000131 |
| prior_b_wt | 0.9999289 |
| lprior | 1.0035482 |
| lp__ | 1.0058151 |
MCMC Chain Resolution
This is the ESS or effective sample size. brms reports two versions: bulk-ESS (for posterior central tendency) and tail-ESS (for tail quantiles like 95% credible intervals). Following Vehtari et al. (2021), the recommended thresholds are bulk-ESS ≥ 1000 and tail-ESS ≥ 400. (We use 4 chains × 1000 post-warmup iterations = 4000 draws by default; ESS counts roughly how many of those draws are effectively independent.)
library(broom.mixed)
tidy(binomial.fit, ess = TRUE) %>% kable(caption="Model random effects for weight vs transmission")| effect | component | group | term | estimate | std.error | conf.low | conf.high | ess |
|---|---|---|---|---|---|---|---|---|
| fixed | cond | NA | (Intercept) | 13.2410331 | 4.523030 | 5.752642 | 23.153613 | 1960.890 |
| fixed | cond | NA | wt | -4.4097313 | 1.442540 | -7.622277 | -2.061720 | 1780.931 |
| fixed | cond | NA | priorwt | -0.0809704 | 4.926627 | -9.631769 | 9.515431 | 3929.666 |
For all model parameters, bulk-ESS and tail-ESS were each greater than 1500 samples, well above the recommended thresholds (≥ 1000 bulk, ≥ 400 tail).
Posterior Distribution
Posterior Predictive Check
Similar to the prior predictive check we should check if our posterior results match the actual results.
pp_check(binomial.fit, type = "dens_overlay",ndraws=100)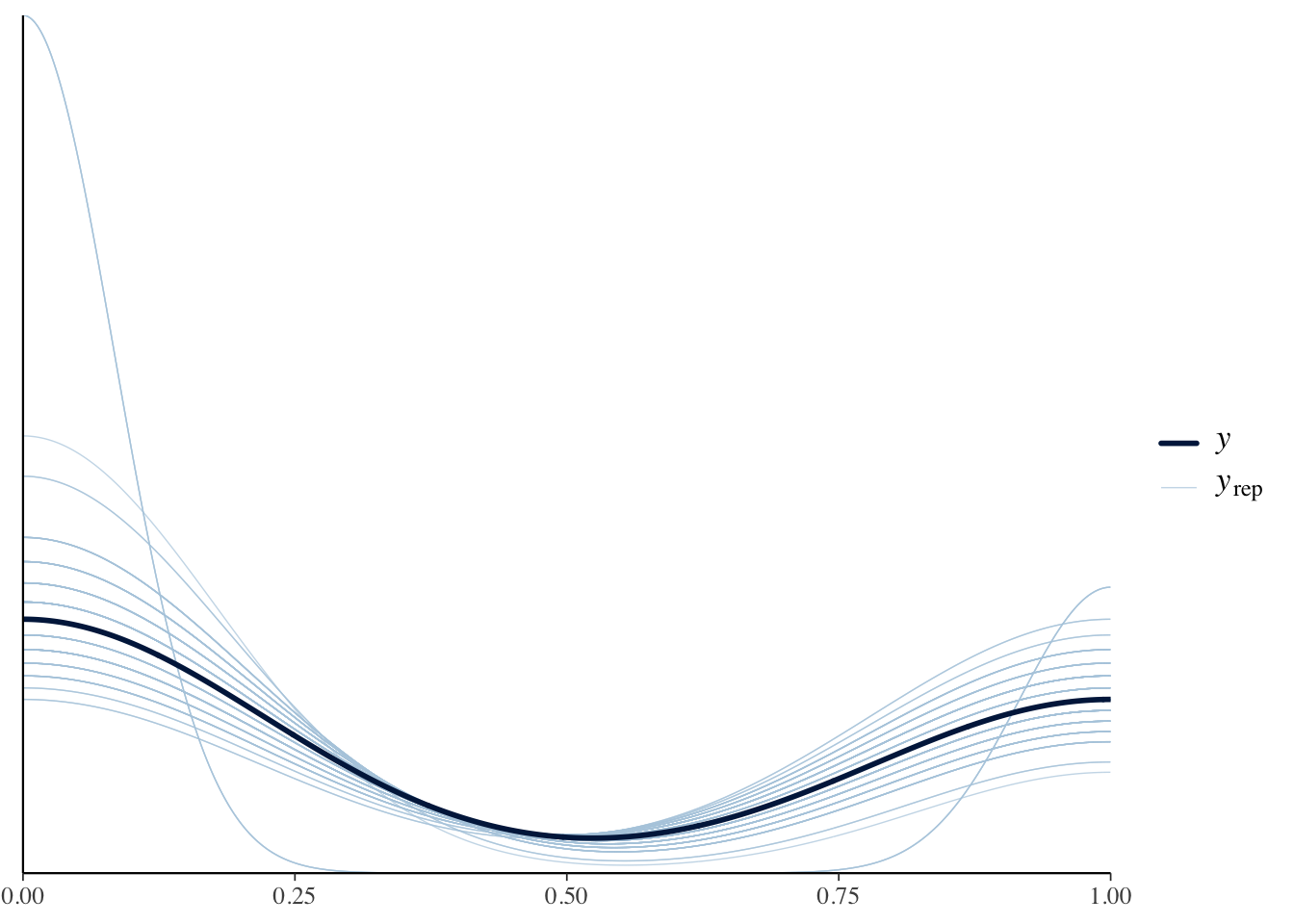
This looks great, with the modeled curve being in the middle of the posterior drawn lines.
A posterior predictive check indicated a good model fit.
Summarize Posterior of Variables
Describe the posterior variables, including their shape, estimates and range.
plot(binomial.fit)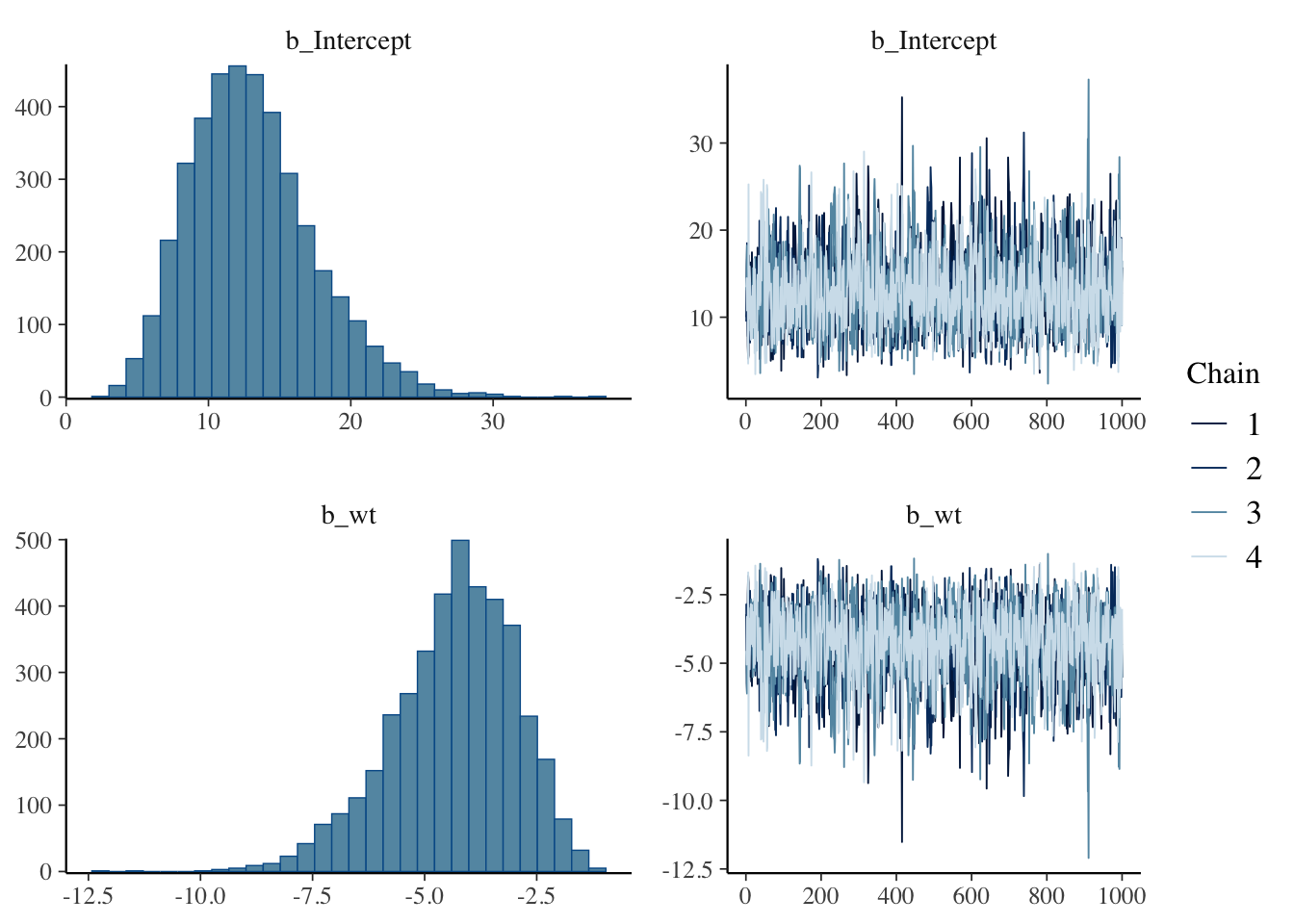
library(ggplot2)
library(cowplot)
b_wt_plot <-
as_draws_df(binomial.fit) %>%
ggplot(aes(x=b_wt)) +
geom_density(fill="#FFCB05") +
geom_vline(xintercept=0,color="#00274C",lty=2) +
labs(y="",
x="",
title="Beta (Weight)") +
theme_classic(base_size=16)
b_int_plot <-
as_draws_df(binomial.fit) %>%
ggplot(aes(x=b_Intercept)) +
geom_density(fill="#FFCB05") +
geom_vline(xintercept=0,color="#00274C",lty=2) +
labs(y="",
x="",
title="Intercept") +
theme_classic(base_size=16)
plot_grid(b_int_plot,b_wt_plot)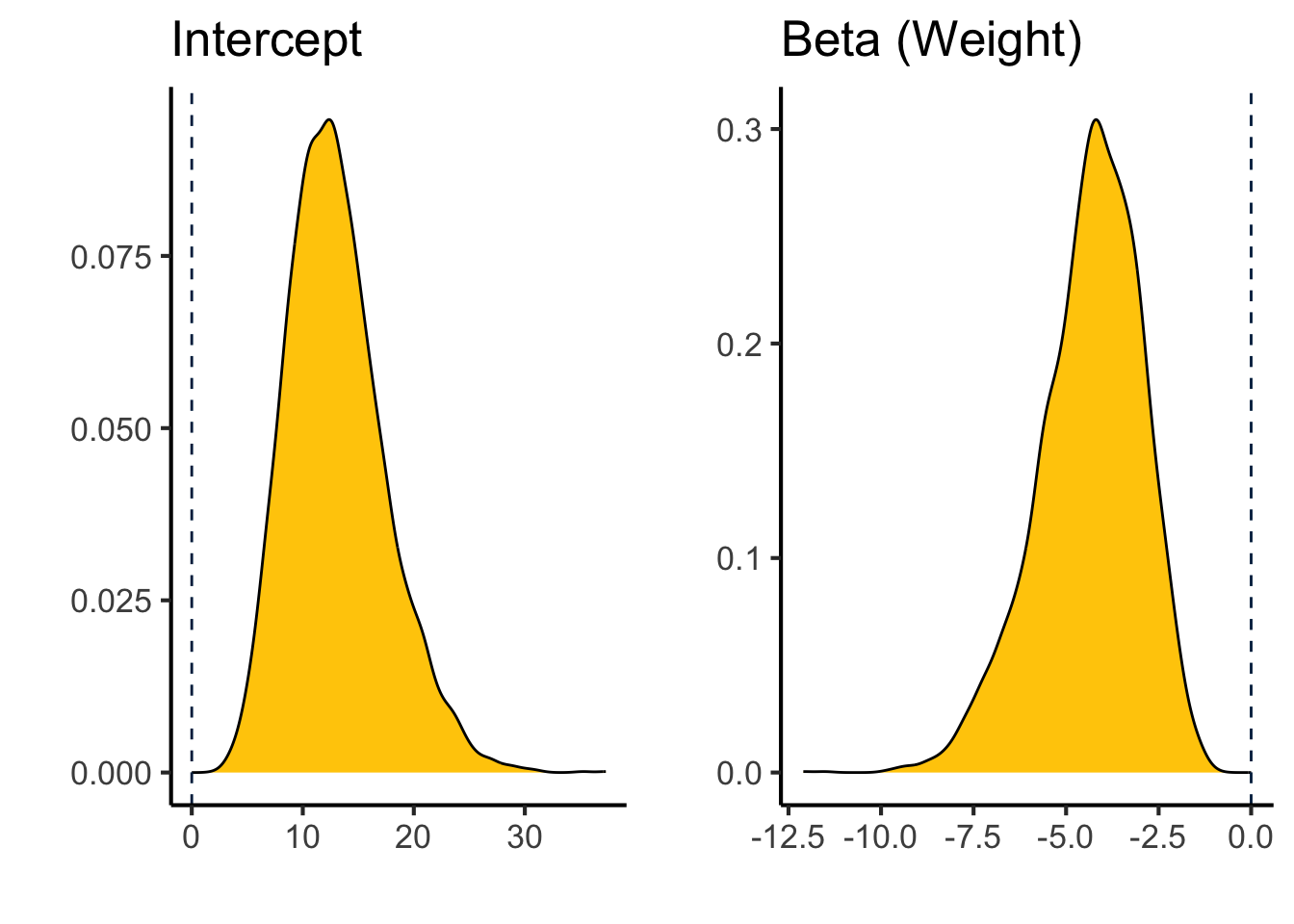
These are both roughly unimodal distributions centered at:
fixef(binomial.fit) %>% kable(caption="Posterior estimates", digits=3)| Estimate | Est.Error | Q2.5 | Q97.5 | |
|---|---|---|---|---|
| Intercept | 13.241 | 4.523 | 5.753 | 23.154 |
| wt | -4.410 | 1.443 | -7.622 | -2.062 |
The beta coefficient for the effect of weight on transmission type is -4.41 with a 95% credible interval of -7.622 to -2.062 (OR = 0.012 per 1000 lb increase in weight).
Bayes Factor and Posterior Probabilities
The Bayes Factor and posterior probabilities are extracted by testing a particular hypothesis
hypothesis(binomial.fit, "wt<0")$hypothesis %>%
kable(caption="Hypothesis test for effects of weight on automatic transmission", digits=3)| Hypothesis | Estimate | Est.Error | CI.Lower | CI.Upper | Evid.Ratio | Post.Prob | Star |
|---|---|---|---|---|---|---|---|
| (wt) < 0 | -4.41 | 1.443 | -7.034 | -2.32 | Inf | 1 | * |
In this case the values are off the scale high so it’s best to report as greater than a large number rather than infinity and zero. Note that since the model predicts P(manual), wt < 0 corresponds to weight decreasing the probability of a manual transmission (equivalently, increasing the probability of an automatic transmission) – the same direction reported in the binomial regression example. This method reports a Savage-Dickey Bayes factor (Wagenmakers et al. 2010), which quantifies the relative evidence (how much the data multiply the prior odds) in favor of one hypothesis over the other.
The Bayes Factor for the hypothesis that higher vehicle weight is associated with a higher probability of an automatic transmission is >1,000,000 with a posterior probability of >0.999.
The best way to characterize your posterior probabilities (depending on your use) are probably these three terms:
- Median estimate and 95% credible interval of your posterior density
- Probability of direction: the posterior probability that the estimate is there is an effect in some direction (positive or negative). Sometimes abbreviated as pd.
- ROPE: The region of practical equivalence, or probability of negligible effect. This region is defined as \(\pm0.1 \times SD\) for continuous variables and \(OR=\pm 0.18\) for a logistic regression. This can be manually defined using
rope_range. These defaults were described in Kruschke (2015).
All three parameters can be calculated using the bayestestR package.
library(bayestestR)
describe_posterior(binomial.fit,
test=c("pd","rope")) |>
kable(caption="Posterior summary for binomial fit", digits=3)| Parameter | Median | CI | CI_low | CI_high | pd | ROPE_CI | ROPE_low | ROPE_high | ROPE_Percentage | Rhat | ESS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| b_Intercept | 12.833 | 0.95 | 5.753 | 23.154 | 1 | 0.95 | -0.181 | 0.181 | 0 | 1.001 | 1938.815 |
| b_wt | -4.301 | 0.95 | -7.622 | -2.062 | 1 | 0.95 | -0.181 | 0.181 | 0 | 1.002 | 1766.969 |
Summary
Here are some recommendations to where to put this information
| Reporting Point | Location |
|---|---|
| Justification | Introduction |
| Goals | Introduction |
| Description of Variables | Results |
| Likelihood Function | Methods |
| Prior Distribution | Methods |
| Formal Specification | Methods or Default |
| Prior Predictive Check | Methods/Repository |
| Software | Methods |
| \(\hat{R}\) | Methods |
| ESS | Methods |
| Posterior Predictive Check | Methods/Repository |
| Posterior Distributions | Results/Repository |
| BF and Posterior Probability | Results |
References
Bürkner, Paul-Christian. 2017. “brms: An R Package for Bayesian Multilevel Models Using Stan.” Journal of Statistical Software 80 (1): 1–28. https://doi.org/10.18637/jss.v080.i01.
Bürkner, Paul-Christian. 2021. “Bayesian Item Response Modeling in R with brms and Stan.” Journal of Statistical Software 100 (5): 1–54. https://doi.org/10.18637/jss.v100.i05.
Gelman, A., and D. B. Rubin. 1992. “Inference from Iterative Simulation Using Multiple Sequences.” Statistical Science 7 (4): 457–72. https://doi.org/10.1214/ss/1177011136.
Kruschke, John K. 2015. Doing Bayesian Data Analysis: A Tutorial with r, JAGS, and Stan. 2nd ed. Academic Press/Elsevier.
Kruschke, John K. 2021. “Bayesian Analysis Reporting Guidelines.” Nature Human Behaviour 5 (10): 1282–91. https://doi.org/10.1038/s41562-021-01177-7.
R Core Team. 2024. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. https://www.R-project.org/.
Wagenmakers, Eric-Jan, Tom Lodewyckx, Himanshu Kuriyal, and Raoul Grasman. 2010. “Bayesian Hypothesis Testing for Psychologists: A Tutorial on the Savage–Dickey Method.” Cognitive Psychology 60 (3): 158–89. https://doi.org/10.1016/j.cogpsych.2009.12.001.
Session Info
sessionInfo()R version 4.6.0 (2026-04-24)
Platform: aarch64-apple-darwin23
Running under: macOS Tahoe 26.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.6/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/Detroit
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] bayestestR_0.17.0 cowplot_1.2.0 ggplot2_4.0.3
[4] broom.mixed_0.2.9.7 brms_2.23.0 Rcpp_1.1.1-1.1
[7] dplyr_1.2.1 knitr_1.51 tinytex_0.59
loaded via a namespace (and not attached):
[1] tidyselect_1.2.1 farver_2.1.2 loo_2.9.0
[4] S7_0.2.2 fastmap_1.2.0 tensorA_0.36.2.1
[7] digest_0.6.39 estimability_1.5.1 lifecycle_1.0.5
[10] StanHeaders_2.32.10 magrittr_2.0.5 posterior_1.7.0
[13] compiler_4.6.0 rlang_1.2.0 tools_4.6.0
[16] yaml_2.3.12 labeling_0.4.3 bridgesampling_1.2-1
[19] htmlwidgets_1.6.4 pkgbuild_1.4.8 plyr_1.8.9
[22] RColorBrewer_1.1-3 abind_1.4-8 withr_3.0.2
[25] purrr_1.2.2 datawizard_1.3.1 grid_4.6.0
[28] stats4_4.6.0 future_1.70.0 inline_0.3.21
[31] emmeans_2.0.3 globals_0.19.1 scales_1.4.0
[34] insight_1.5.0 cli_3.6.6 mvtnorm_1.3-7
[37] rmarkdown_2.31 reformulas_0.4.4 generics_0.1.4
[40] otel_0.2.0 RcppParallel_5.1.11-2 rstudioapi_0.18.0
[43] reshape2_1.4.5 rstan_2.32.7 stringr_1.6.0
[46] splines_4.6.0 bayesplot_1.15.0 parallel_4.6.0
[49] matrixStats_1.5.0 vctrs_0.7.3 Matrix_1.7-5
[52] jsonlite_2.0.0 listenv_0.10.1 tidyr_1.3.2
[55] glue_1.8.1 parallelly_1.47.0 codetools_0.2-20
[58] distributional_0.7.0 stringi_1.8.7 gtable_0.3.6
[61] QuickJSR_1.9.2 tibble_3.3.1 pillar_1.11.1
[64] furrr_0.4.0 htmltools_0.5.9 Brobdingnag_1.2-9
[67] R6_2.6.1 Rdpack_2.6.6 evaluate_1.0.5
[70] lattice_0.22-9 rbibutils_2.4.1 backports_1.5.1
[73] broom_1.0.12 rstantools_2.6.0 coda_0.19-4.1
[76] gridExtra_2.3 nlme_3.1-169 checkmate_2.3.4
[79] xfun_0.57 forcats_1.0.1 pkgconfig_2.0.3